Acoplamento é a causa raiz de boa parte dos problemas relacionados a disponibilidade, manutenabilidade, performance e resiliência. Acoplamento não tratado é fonte de custo tanto para o desenvolvimento quanto para a sustentação de soluções.
Conforme Conway, software com componentes acoplados é resultado do trabalho de times acoplados. Não raro, esses times tem “pontos de falha” e “gargalos” bem conhecidos. A correta organização dos times, permitindo que esses operem de maneira independente, inclusive disponibilizando seus produtos de maneira independente é a essência para combater o acoplamento.
Há mais de uma década, arquiteturas baseadas em microsserviços tem permitido o estabelecimento de times com mais autonomia para entregar mais valor para o negócio. Também há mais de uma década, implementações infelizes desse estilo arquitetural tem destruído valor.
Conceito fundamental
Microsserviços é um estilo arquitetural que preconiza o desenvolvimento de aplicações a partir de serviços pequenos, cada um rodando em seu próprio processo, que se comunicam através de mecanismos leves.
REST (HTTP resource API) ou gRPC
Comunicação intensiva entre serviços utilizando a combinação HTTP/1.1 e JSON é um “pedido” para problemas de performance. Seja pelas limitações do protocolo de comunicação ou pela “verbosidade” do formato JSON.
Recentemente, têm ganho destaque a utilização de gRPC (que opera sobre HTTP/2) combinada protocol buffers.
Estrategicamente, microsserviços precisam ser construídos para suportar capabilities de negócio. Essa característica é essencial para que sejam desenvolvidos e tenham deploys independentes.

Importante destacar que esse estilo arquitetural habilita tamanha independência autorizando, inclusive, que cada microsserviço seja escrito em uma linguagem de programação diferente com tecnologias de persistência exclusivas.
API Layer
A maioria das arquiteturas baseadas em microsserviços implementa alguma forma de “camada de API”, muitas vezes implementadas por um API Gateway, conectando usuários externos (interfaces ou sistemas de terceiros) aos microsserviços. Trata-se de uma abordagem opcional, mas recomendada.
Essa estratégia permite a criação facilitada de APIs externas, facilitando a adoção, além de poder implementar shared concerns como autenticação e localização. Entretanto, é importante destacar que não devem ser atribuídas a essa camada responsabilidades de orquestração.
Relação com Squads
A lei de Conway é categórica e suas implicações são óbvias: Uma organização monolítica não consegue produzir microsserviços. Empresas que produzem softwares monolíticos não deveriam ter “squads”.
Squad
Squads são times pequenos, com grande autonomia, multi-disciplinares que operam dando ênfase a agilidade no lugar metodologias e, também, princípios no lugar práticas. Eles resultam produtos, não projetos, por isso são responsáveis por todo o ciclo de vida (end-to-end) .
O termo foi lançado pelo Spotify e é conceito central da celebrada cultura de engenharia da empresa.
Para ter autonomia, as “entregas” de um squad devem ocorrer de forma independente. Se as entregas de um squad precisarem ser feitas com as de outros, acordos são necessários e a burocracia-para-confiança emerge.
Apenas times realmente autônomos conseguem produzir (micros)serviços com baixo acoplamento. Microsserviços com alto acoplamento não se justificam pois são, apenas, um pesadelo para a operação.
São necessários times realmente independentes para produzir (micros)serviços que não compartilham banco de dados.
A comunicação entre (micros)serviços será naturalmente assíncrona, se a comunicação entre os times que os produzem também for. Comunicação síncrona entre (micros)serviços revela, mais que possível falha de design de software, falha de design organizacional.Quando um squad desenvolve muitos microsserviços
Por mais que se tome cuidado no processo de elaboração da arquitetura, muitas vezes são as estruturas organizacionais, formadas a partir de áreas de especialidade, que levam times a desenvolver microsserviços que atendem apenas demandas locais.

Na prática, as “comunidades” da organização tendem a se replicar na estrutura dos serviços criando pontos de interface restritos com alta centralidade.
De qualquer forma, é importante recordar que microsserviços de boa qualidade implementam, de forma desacoplada, capabilities das organizações. Logo, deveriam ser úteis muito além das fronteiras dos times que os desenvolveram, reduzindo a centralidade e, de maneira geral, colaborando para mitigação de pontos de fragilidade.
A identificação de “comunidades de microsserviços” pode e deve ser facilitada pelo acompanhamento dinâmico e contínuo dos coeficientes de agrupamento local.
Coeficiente de agrupamento local
Na teoria dos grafos, o coeficiente de agrupamento (clustering coefficient) mede o grau com que os nós de um grafo tendem a agrupar-se.
O coeficiente de agrupamento local de um vértice (nó) num grafo mede o quão perto os seus vizinhos estão de serem um clique (grafo completo). Por outras palavras, pode dizer-se que o coeficiente de agrupamento local mede o grau da densidade de ligações da vizinhança de um determinado nó, isto é, corresponde ao grau com que os vizinhos de um nó se interligam.
O coeficiente de agrupamento local de um microsserviço é calculado como sendo a proporção das ligações existentes entre os microsserviços que este acessa em relação com o total das ligações possíveis. Quando maior for o coeficiente, maiores são os indícios de formação de “comunidade”.

Quanto maiores forem os coeficientes de agrupamento local, por correlação, maiores são as chances de changing coupling que podem ser verificados nos controles de versão. Consequentemente, mais intensos devem ser os questionamentos quanto ao “reagrupamento” das bases de código.
A comprovação sistemática e recorrente de coeficientes de agrupamento elevados deve implicar em estudos mais aprofundados das causas. Não é incomum que a formação de “comunidades de microsserviços” indique deterioração no relacionamento entre os times da organização e, disto, a demanda por revisões da estrutura organizacional. Outra possibilidade é que o “olhar” dos times, embora com sistemas distribuídos, permaneça “viciado” em uma estrutura monolítica, indicando ações de desenvolvimento de pessoas das equipes técnicas.
Implicações para a reutilização
Uma das “fontes inocentes” para acoplamento é a insistência por alternativas para reutilização.
O trade-off negativo da reutilização é o acoplamento. Quando um arquiteto projeta um sistema favorecendo o reuso, ele também favorece ao acoplamento para permitir esse reuso, seja por herança ou composição. (Neal Ford)
Toda alternativa de reutilização faz emergir um componente com acoplamento aferente elevado que, mais cedo ou mais tarde, se converte em “gargalo” para o desenvolvimento.
A emergência por alternativas para a gestão de componentes deu origem a iniciativas de inner sourcing.
Reutilização de recursos operacionais
A opção por duplicação frente a reutilização é válida para artefatos funcionais, mas não para recursos operacionais (tais como logging e monitoramento). A abordagem comum é manter recursos funcionais “dentro” dos microsserviços, duplicados sempre que necessário, e recursos operacionais “fora”, em sidecars.

Sidecar Pattern
O padrão sidecar propõe a “entrega” de uma solução (no nosso contexto, microsserviço) composta por dois contêineres.
O primeiro contêiner contem a lógica core da aplicação. Sem este contêiner a solução simplesmente não existe. O segundo contêiner é o sidecar. Ele amplia ou melhora os entregáveis do contêiner de aplicação, muitas vezes sem o conhecimento deste.
A “padronização” de um único sidecar em dois ou mais microsserviços permite a inclusão de componentes para administração.

A “predominância” de um único sidecar habilita a formação de service meshs.
Istio
Uma das plataformas mais utilizadas para adoção de Service Mesh é o Istio. Ele estende o Kubernetes para estabelecer uma rede programável, usando o proxy de serviço Envoy. Ele oferece gerenciamento de tráfego universal, telemetria e segurança para implantações complexas.
Arquitetura naturalmente distribuída
Em produção, microsserviços operam em forma naturalmente distribuída. Afinal, cada serviço “roda” em um processo independente, originalmente, em um computador dedicado, mas, atualmente, em máquinas virtuais ou contêineres.
Quando muitos serviços compartilham recursos computacionais em demasia, rodando em uma única plataforma operacional, têm-se, inicialmente, melhor aproveitamento da largura de banda da rede, memória, discos, etc. Entretanto, na medida em que as demandas de cada serviço crescem, ocorrem restrições que podem levar a problemas de disponibilidade e aumentam a importância de adotar táticas de resiliência.
Sem o devido cuidado, aplicações baseadas em microsserviços podem ter, devido a natureza distribuída, problemas de performance. Afinal de contas, chamadas na rede são muito mais custosas que chamadas a métodos, além de todo o overhead de segurança e governança.
Oito falácias da computação distribuída
Em 1994, Peter Deutsch, que trabalhou na Sun Microsystems, consolidou uma lista de 7 falácias frequentemente associadas a sistemas distribuídos. Mais tarde, em 1997, James Gosling adicionou um item a essa lista, criando a comumente conhecida relação das oito falácias da computação distribuída. São elas:
- A rede é confiável
- A latência é zero
- A largura de banda é infinita
- A rede é segura
- A topologia da rede nunca muda
- Existe um administrador
- Custo de transferência de dados é zero
- A rede é homogênea
Relação com Domain-driven Design
A decomposição de um sistema em microsserviços implica em tolerar duplicação como antídoto para o acoplamento. Além disso, devido aos problemas comuns à sistemas distribuídos, implica em organizar componentes de forma a minimizar a quantidade de transações envolvendo serviços. Daí a importância de utilizar estratégias cuidadosas para definir níveis de granularidade e critérios de decomposição.Uma abordagem que tem ganho em popularidade é a utilização de Domain-driven Design, fazendo com que microsserviços implementem total ou parcialmente elementos de um contexto delimitado (bounded context).
Em um monólito, é comum que os desenvolvedores compartilhem classes comuns, com baixo valor semântico, entre partes distintas do aplicativo. No entanto, em sistemas baseados microsserviços, com vistas a evitar o acoplamento, a duplicação é preferível.
Origem do termo monolítico
O termo “monolítico”, bastante utilizado para designar sistemas projetados em oposição aos conceitos relacionados a microsserviços, foi inicialmente utilizado por Eric Raymond no clássico “The Art of Unix Programming“.
Implicações para governança
A natureza distribuída, do software e dos times, estabelece uma tendência a não-padronização das tecnologias adotadas. Por um lado, isso é uma coisa boa, afinal, fica mais fácil utilizar a tecnologia certa para cada problema. Por outro, pode acender “resistências” em empresas com culturas passionais ou burocráticas.
O radar de tecnologia
Um radar de tecnologia é um guia com opiniões sobre tecnologias e tendências que impactam a indústria. O método foi criado pela ThoughtWorks e têm edições fornecidos pela consultoria. Entretanto, é livre para confecção dentro de cada empresa indicando técnicas, ferramentas, plataformas, linguagens & frameworks.
Relação com Cloud Native Computing
Uma solução cloud native utiliza stacks de tecnologia open source para distribuir aplicações, como microsserviços, colocando suas partes em contêineres apropriados, dinamicamente orquestrados como forma de otimizar a utilização de recursos. Não se trata de como são organizados servidores (que estão “na nuvem”), mas, sim, como são organizados os serviços.
Práticas cloud native são mais fáceis de implementar em aplicações desenvolvidas com microsserviços. Aliás, há quem considere princípio essencial junto como adoção de plataformas, contêineres, orquestradores e automação.
Relação com DevOps
Não percamos de vista que microsserviços tem como objetivo central reduzir acoplamento. Estruturas organizacionais desfavoráveis, entretanto, acabam “forçando” acoplamento emergente. Por exemplo, times centralizados para gerenciar bancos de dados e operações “gargalam” a estrutura, “monolitizando” administração dos bancos e gestão do ambiente produtivo.

O esforço em microsserivços implica na eliminação dessas “barreiras”. Logo, segundo Conway, o idela é trazer operações para dentro das Squads, conciliando com atividades de desenvolvimento.

Evoluindo soluções baseadas em SOA com ESBs
Ponto de partida
Embora se confronte muito a ideia de arquiteturas baseadas em microsserviços com aplicações monolíticas, este não é o debate mais comum na maioria das organizações de maior porte. Estas, com frequência, têm histórico de implantação de alguma variante de arquitetura baseada em serviços (SOA).

Embora existam pequenas variações, as implementações legadas geralmente estão associadas as seguintes caracerísticas:
- Um conjunto de sistemas, geralmente em tecnologia legada, junto com sistemas mais novos, alguns até rodando na nuvem, suportam o negócio da organização.
- Sobre o conjunto de aplicações legadas, um conjunto de serviços apresentam interfaces de negócio para suportar processos, inicialmente de integração, que “expõe” os sistemas de base com algum nível de governança
- A comunicação entre os diversos sistemas legados é viabilizado por um ESB (geralmente corporativo, bem “caro”, e de um fornecedor de grande nome). Esse “ESB” entrega um conjunto de features incluindo, além de mensageria, políticas de governança, transformação de dados, segurança (autenticação e autorização), etc.
- Um conjunto de aplicações clientes se comunica com os serviços, geralmente através da ESB.
Cada um dos sistemas da empresa e, muitas vezes, muitos dos serviços são mantidos como monolíticos locais, cada um com seu banco de dados.
Não é raro que os sistemas sejam desenvolvidos em tecnologias legadas (MUMPS, COBOL, etc.) Os serviços geralmente estão implantados usando protocolos pesados, como SOAP.
Recentemente, as pressões da Transformação Digital tem levado as empresas a adicionarem uma camada extra a arquitetura indicada acima. Na tentativa de se tornarem mais “abertas”, conectadas e digitais, as empresas estão fornecendo APIs para facilitar a conexão com seus clientes.
 Problemas a superar
Problemas a superar
 Problemas a superar
Problemas a superarConsiderando que a lei de Conway seja válida, é bem difícil suportar uma organização para manter a arquitetura descrita acima.
Invariavelmente, os sistemas legados, cedo ou tarde, se convertem em gargalos e acabam sendo mantidos por “silos”, as vezes bem intencionados, com gente que se esforça para suportar o ritmo de modificação de dados demandado pelas “novas APIs”. Entretanto, não é raro que recursos de “contingenciamento” precisem ser implantados de forma que os modificações fiquem represadas por mais tempo que o ideal para o negócio.
Também não é incomum que o ESB acabe assumindo muito mais tarefas do que deveria (sobretudo aplicação de regra de negócio).
Por que microsserviços são recomendados nesse cenário?
Para cenários descritos acima, microsserviços parecem fazer sentido, primeiro pelo aspecto organizacional (autorizando a ideia de eliminar silos de TI).
Outro ponto importante e que não pode ser ignorado é que a arquitetura descrita acima é cara para manter e, sobretudo, para atualizar. Não é incomum encontrarmos empresas onde o “negócio” deseja acelerar o ritmo das mudanças (o que é um imperativo) mas não conseguem em função do “peso” da tecnologia.
Abaixo a ESB!
Boa parte da complexidade vista até aqui reside no fato de termos “dois mundos” (APIs e “sistemas pesados”) separados por uma fronteira bem demarcada (a ESB e os serviços).
Em uma análise simples, essa separação em “dois mundos” deixa os sistemas difíceis de manter. Geralmente, alterações de negócio começam nas aplicações “consumidoras” e são desencadeadas “API” abaixo, geralmente travando nos “sistemas pesados” que são “micro-monolitos”.
Por todo o exposto, parece lógico que, para acabar com a “separação dos mundos” ou, pelo menos, reduzir as barreiras, o primeiro passo seja derrubar a fronteira! Ou seja, colocar fim no ESB.
As ESBs, ao longo do tempo, foram acumulando “inteligência demais”, ficando responsáveis por estratégias de roteamento, transformação (enriquecimento e mudança de formato) e até mesmo a aplicação de lógica de negócio.
O bom design de microsserviços faz com que eles não utilizem mais a ESB como estratégia de comunicação. Toda a lógica de negócio e técnicas de transformação que, tradicionalmente, residem na ESB são transferidas para microsserviços.
Adotando “Smart endpoints & Dumb Pipes”
A visão de “derrubar” o ESB usando microsserviços, não é nova, nem original. Martin Fowler já descreveu essa estratégia anos atrás.
Em uma arquitetura baseada em microsserviços, a comunicação ocorre sempre por meio de protocolos leves ou por mecanismos mais “puros” de mensageria (dumb pipes). Enquanto isso, routing e transformação de mensagens acontecem através de microsserviços (smart endpoints).
Logo, o primeiro passo para “aliviar” a estrutura seja substituir o combinado de ESB + serviços por uma camada de microsserviços.

Essa estratégia tem, obviamente, seus prós e contras. Sendo que o principal “contra”, talvez, seja o aumento da complexidade para a governança. Por outro lado, a adoção dos microsserviços no lugar da combinação ESB + Serviços, aproxima a implementação dos sistemas base das APIs e tende a reduzir o peso da infraestrutura.
Implicações para a organização dos times
Toda mudança na estrutura de comunicação de um software implica em modificações na estrutura de comunicação da empresa que o desenvolve. Logo, uma alteração como a que estamos propondo no software acaba mudando o shape da organização.
Ter APIs, ESB+serviços e sistemas legados leva a maior parte das organizações a ter, pelo menos três categorias de time: 1) Desenvolvedores de API, 2) Especialistas em Integração e 3) Desenvolvedores dos sistemas legados.
A mudança da arquitetura proposta, substituindo ESB + serviços, por microsserviços tende a fundir os times de desenvolvimento de APIs com os especialistas de integração simplificando as estruturas de comunicação da organização.
Transformando monólitos em microsserviços passo-a-passo
Proxy HTTP: um primeiro passo seguro
Um dos grandes desafios para migração de sistemas monolíticos para arquiteturas baseadas em microsserviços é o uso ampliado dos recursos de rede. Por isso, em uma migração gradual, um ótimo primeiro passo é assegurar que a infraestrutura utilizada pela organização não será um empecilho.
Nesse contexto, quando um sistema monolítico expõe funcionalidades através de APIs HTTP (ou qualquer outro protocolo formal de comunicação), é recomendável que implementemos um proxy. Caberá a ele interceptar todas as requisições para esse serviço, transmitindo-as para ele na sequência, aguardando seus retornos, para, então, retornar para as aplicações clientes.
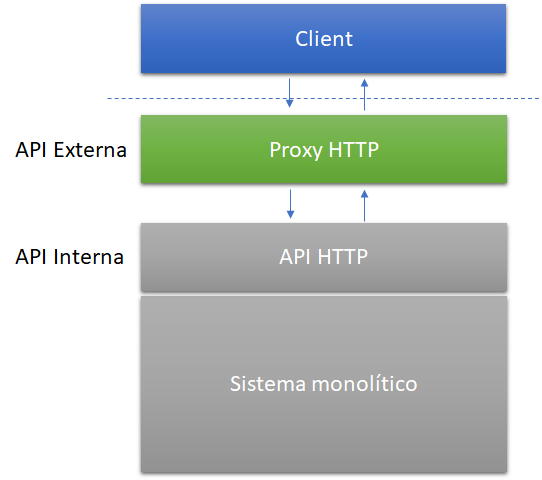
Essa recomendação, formalizada recentemente por Sam Newman – uma das maiores autoridades mundiais em microsserviços – permite identificar muito cedo eventuais problemas de infraestrutura além de possuir custo mínimo, tanto técnico quanto para o negócio. Além disso, tem complexidade minimizada por sua alta reversibilidade.
Eventualmente, o proxy poderá redirecionar requisições para que sejam atendidas por um microsserviço que implementará uma funcionalidade extraída do monólito. Tudo isso de maneira transparente tanto para as aplicações clientes quanto para a própria aplicação monolítica que mantém (por algum tempo) a implementação original.
Finalmente, com o tempo, o proxy também poderá evoluir e se adaptar melhor as necessidades das aplicações clientes, operando como uma API externa.
Segregando funcionalidades
Paralisia por análise
A paralisia de análise (ou paralisia por análise) descreve um processo individual ou de grupo quando a análise excessiva ou o pensamento excessivo de uma situação podem fazer com que o movimento para a frente ou a tomada de decisão se tornem “paralisados”, significando que nenhuma solução ou curso de ação é decidido. Uma situação pode ser considerada muito complicada e uma decisão nunca é tomada, devido ao medo de que um problema potencialmente maior possa surgir.
Uma pessoa pode desejar uma solução perfeita, mas pode temer tomar uma decisão que possa resultar em erro, enquanto está no caminho para uma solução melhor.
Uma vez que se constate que a adoção de microsserviços se justifica, quanto antes houver algo que se assemelhe a um microsserviço em produção, melhor. Afinal, antes serão discutidos aspectos relacionados com a operação, fazendo com que práticas de DevOps aconteçam por necessidade e não por imposição.

Sam Newman indica que a primeira implementação de um microsserviço, em um processo de migração, pode ser uma extração simples de lógica da aplicação monolítica, ainda compartilhando a mesma base de dados. Essa “preservação” do esquema original, aliás, facilita a separação dos processos de deploy e release permitindo que o microsserviço seja “desligado” com prejuízos mínimos quando se algo der errado.
Em um cenário ideal, o acionamento do microsserviço será responsabilidade de um proxy http que esteja interceptando todas as requisições para o sistema. Esse proxy, por sua vez, deverá condicionar a utilização do microsserviço a uma ou mais feature toogles.
Por algum tempo, atividades de consulta sem modificação de estado podem, inclusive, ocorrer simultaneamente no microsserviço e no monólito. Dessa forma, será possível verificar no proxy se a nova implementação está em conformidade com a antiga.
Você não apreciará o verdadeiro horror, dor e sofrimento dos microsserviços até que esteja executando-os em produção – Sam Newman
O esforço para colocar um microsserviço em produção antecipa e explicita as debilidades do sistema monolítico que se está evoluindo, sobretudo os pontos de acoplamento.
Isolando o banco de dados
É plenamente razoável que uma primeira implementação ainda acesse diretamente, por exemplo, a base de dados do sistema monolítico. Além disso, é muito importante que o acesso ao microsserviço aconteça através de um proxy http que possa redirecionar a carga em caso de problemas.
O sucesso no cumprimento dessas recomendações indica que já foram identificados e resolvidos eventuais limitações do ambiente, sobretudo na rede. Além disso, é indicativo de que a organização já acumulou volume de experiência para operar em sistemas cada vez mais distribuídos.
Essa estratégia, entretanto, tem como principal ponto negativo o grande acoplamento entre o monólito e o microsserviço em função do acesso direto do banco de dados. Afinal, nenhum dos times (monólito e microsserviço) poderá, por exemplo, fazer ajustes no schema das bases sem causar um problema em potencial para o outro.
O próximo passo lógico passa a ser, então, “trocar dívidas técnicas caras por outras mais baratas”. Começando por restringir acesso a base de dados do sistema monolítico! Para que isso ocorra rapidamente, como se tempo e dinheiro fossem importantes, o time que mantém o monólito deverá fornecer uma API de consulta especificamente para atender as demandas do novo microsserviço.
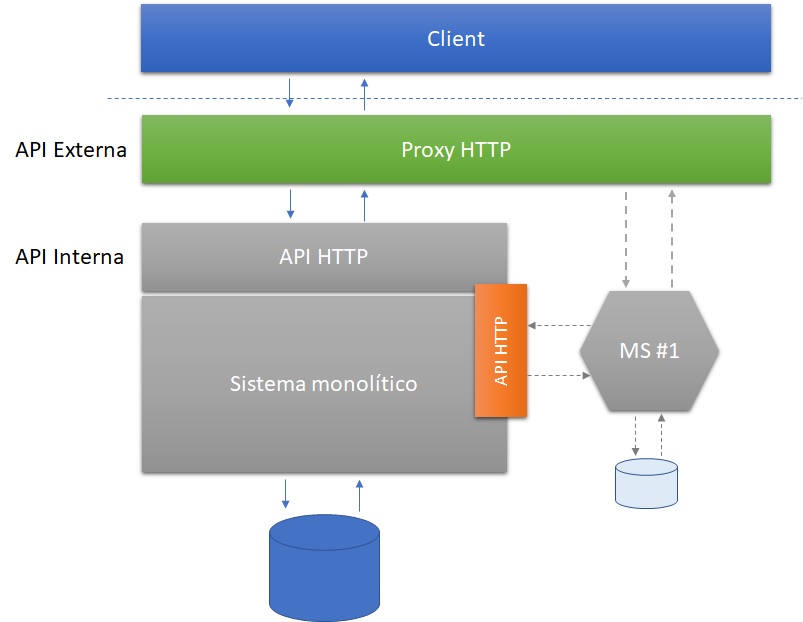
Com o microsserviço acessando dados exclusivamente através de uma API, sem ir diretamente ao banco de dados, o time que mantém o monólito recupera a liberdade de promover modificações de schema com chances menores de quebras. Eventualmente, o microsserviço pode adotar, do seu lado, alguma estratégia de caching começando a materializar o que poderá vir a ser, em futuro próximo, seu próprio banco de dados.
É recomendável, que esse “direcionamento a API” seja controlado, no microsserviço, por uma feature toggle. Ou seja, o microsserviço deve poder redirecionar seu consumo novamente para a base de dados em casos de instabilidade.
A partir da modelagem da API fornecida pelo monólito será possível identificar 1) dados consumidos exclusivamente no monólito; 2) dados consumidos exclusivamente pelo novo microsserviço e 3) Dados usados tanto no monólito quanto no microsserviço. Em nossa experiência, esse é um exercício muito útil para identificar falhas evidentes de segregação de responsabilidades.

Importante destacar que o que estamos recomendando aqui é a troca uma dívida técnica mais cara (o acesso direto do microsserviço ao banco de dados do monólito) por uma mais barata (aumento da rede). Entretanto, esse é um passo intermediário importante, tanto para validação da modelagem, como para confirmar a “saúde” da infraestrutura.
Removendo implementações em duplicidade
Uma vez que um time, transformando um monólito em microsserviços, tenha efetivamente, 1) adotado práticas e técnicas para desassociar os processos de deploy e release; 2) colocado um “primeiro” microsserviço imperfeito em produção e 3) controlado acessos a base de dados; devemos garantir que todo “código morto” no monólito seja eliminado e garantir que os times técnicos estejam devidamente estruturados para suportar a evolução.
Na prática, features originalmente providas pelo monólito, agora são providas pelo novo microsserviço e devem ser removidas do sistema original o quanto antes. O momento ideal é quando já houverem evidências de que a nova implementação já é confiável o suficiente.

Para reduzir a chance de “quebras” em outros sistemas, entretanto, é aconselhável não remover imediatamente o acesso às features fornecido pelas APIs internas do monólito. No lugar disso, é coerente modificar essas APIs para que consumam o novo microsserviço.
Importante indicar que todas as medidas adotadas até aqui aumentam consideravelmente a pressão sobre a rede. Entretanto, sistematicamente, estão sendo superadas etapas de transformação e a condição atual é intermediária. Daqui para frente, as medidas técnicas vão na direção de reduzir essa pressão. O processo de transformação de um monólito em microsserviços consiste na troca, contínua e sistemática, de dívidas técnicas mais caras por outras mais baratas.
A pressão sobre a infraestrutura “grita” pela adoção de práticas efetivas de DevOps. Não consideramos viável, nem mesmo responsável, adotar microsserviços sem reduzir as distâncias entre desenvolvimento e operação.
Em termos organizacionais, a evolução da arquitetura deve impactar na “forma” da área técnica. A mesma segmentação que for aplicada nos sistemas deve estar sendo replicada naturalmente nos times que precisam buscar operar da maneira mais independente possível. Geralmente, a parte do time que mantinha o código eliminado do monólito, agora deve se concentrar em manter o microsserviço da forma mais independente possível. É fundamental que seja compreendido que se a estrutura de comunicação da organização não refletir, da forma mais direta possível, a estrutura do software que ela produz, o fracasso é uma certeza!

Por outro lado, quanto maior a relação entre as estruturas de comunicação dos times técnicos e a estrutura de componentes do software sendo desenvolvido, maiores as chances de sucesso.
Todo acoplamento que persistir entre monólito e o novo microsserviço se refletirá em dificuldades de comunicação entre os times e isso é ótimo! Afinal, aumentará a urgência por revisões na arquitetura para “reduzir a dor”. Toda ação irá refletir em iniciativas para reduzir a “dependência”, sobretudo para o deploy, e o impacto sobre o velocity é potencialmente brutal.
Implementando observabilidade
O racional de converter um monólito em microsserviços é transferir parte da complexidade do desenvolvimento para a operação. Afinal, microsserviços tem menos código para entender, logo, desde que pouco acoplados, individualmente, são mais baratos de manter. Em compensação, quanto mais processos para “operar”, mais complexa se torna a operação. Daí a emergência para, em contextos com microsserviços, adotar técnicas modernas compatíveis com DevOps.
Em produção, quando diversos microsserviços são necessários para atender requisições ou demandas de processamento concorrentes, se amplificam os desafios de entender, justificar e solucionar problemas de performance ou falhas.

A adoção de técnicas convencionais de logging em cada microsserviço torna a análise quase impossível, principalmente em sistemas sob stress, gerando mais ruído do que sinal da comunicação. Para agravar o problema, a adoção de microsserviços tem o efeito colateral, geralmente desejável e positivo, da reestruturação dos times de desenvolvimento, em grupos menores e mais segmentados. Não é raro, em condições de stress, onde “algo não vai bem”, brotarem acusações e fugas de responsabilidade.
A solução é substituir técnicas convencionais de logging por abordagens mais sofisticadas. Em sistemas distribuídos, como os baseados em microsserviços, o tracing precisa ser consolidado. Ou seja, é necessário adotar técnicas e tecnologias que permitam verificar a história completa de cada requisição e processamento, passando por todos os microsserviços, mostrando claramente os intervalos de tempo transcorridos entre o início e o fim de cada interação, de forma integrada e centralizada.

Há diversas iniciativas para produzir esse tipo de análise. Modernamente, há uma tendência consolidação de padrões e protocolos abertos que devem ser seguidos e implementados, como o OpenTracing.
Bem implementadas, essas tecnologias permitem identificar rapidamente origens de lentidão ou de falhas de processamento.
Manter sistemas distribuídos sem uso de ferramentas eficientes para observabilidade é como dirigir, a noite, com chuva, em uma estrada cheia de curvas, com faróis apagados.
Estratégias para iniciar a segregação de dados
Extrair um microsserviço de um monólito implica, invariavelmente, na revisão de como os dados são organizados e armazenados. Entretanto, é razoável postergar mudanças mais concretas até o último momento responsável.
Até a estabilização funcional do sistema, é recomendável que nenhuma alteração duradoura seja feita. Isso significa que os dados devem permanecer, majoritariamente, na base de dados do monólito. Dessa forma, fica mais viável, inclusive, desvincular os processos de deploy e release do novo microsserviço, direcionando o tratamento das requisições ao monólito ou ao microsserviço, através de feature toggles.
Inicialmente, as demandas de acesso a dados do microsserviço podem ser atendidas com consultas diretas a base de dados original. Entretanto, assim que possível, o fluxo de dados deve ocorrer por uma API interna, desenvolvida para esse propósito. Nesse caso, estratégias agressivas de caching , se bem implementadas, reduzem o impacto na rede.
Com o tempo, entretanto, assim que for possível remover blocos de código que implementam features do monólito que foram desativadas em função do novo microsserviço, ficará difícil justificar o “telefone sem fio”, sobretudo em função da interdependência desnecessária entre os sistemas e, mais grave, entre os times.
Assumindo o monólito e o microsserviço como dois processos distintos, há dados que:
- continuam fazendo sentido apenas para o monólito;
- fazem sentido apenas para o microsserviço;
- dados que são de uso nos dois contextos.
A partir dessa classificação, fica um pouco mais fácil estabelecer estratégias para a segregação de bases, promovendo isolamento adequado.
Tratamento de dados de uso exclusivo do monólito ou do microsserviço
Idealmente, a modificação de dados no sistema acontece acompanhando a execução dos processos da organização. Nesses casos, as interfaces com o usuário são naturalmente desvinculadas e os dados, associados ao microsserviço ou ao monólito, se estes estiverem bem modelados, são “inputados” de forma independente.

Há, entretanto, cenários onde as interfaces “acoplam” a inclusão de dados de interesse do monólito e do microsserviço a uma única operação. Isso é especialmente comum em sistemas grandes com “telas de cadastro” gigantescas. Sempre que possível, o ideal seria “redefinir” a experiência do usuário conforme o processo. Entretanto, a adequação da interface nem sempre está sob comando e controle dos times internos. Em cenários assim, o jeito é desenvolver uma API externa que continue oferecendo a “interface unificada” para os frontends, enquanto o controle da “saga” fica a cargo de uma camada de mediação que orquestra as APIs internas.
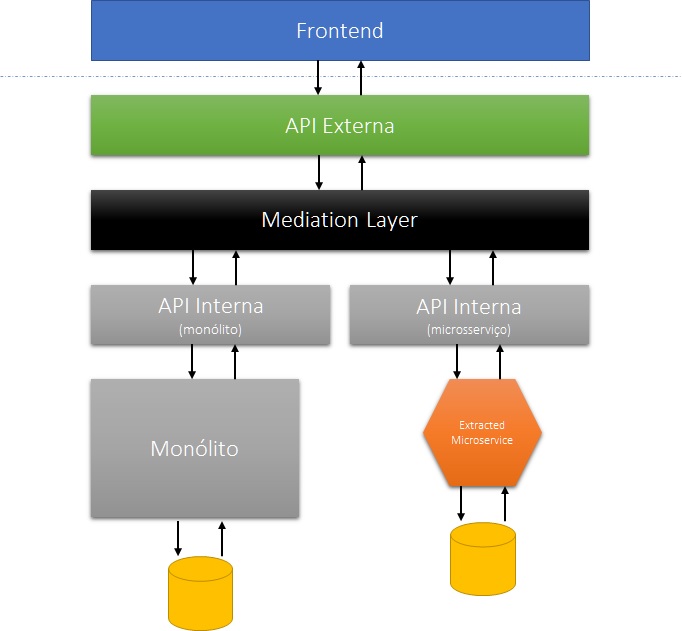
Tratamento de dados compartilhados pelo monólito e pelo microsserviço
Quando um dado é relevante tanto para o monólito quanto para o microsserviço, é necessário identificar em qual contexto ele “nasce”. Deve ser nesse contexto que, por padrão, o dado deverá ficar armazenado. Em caso de dúvidas razoáveis, recomendamos que a opção padrão seja gravar os dados no monólito.
A disponibilização de dados de um contexto para outro pode acontecer de diferentes formas. A mais simples, é através do fornecimento de uma API interna para consulta combinada, se possível, com alguma estratégia agressiva de caching.
Invariavelmente, nesses cenários, é relevante considerar a implementação de modelos de atualização baseados em notificações por eventos.
Indicações e contraindicações
O estilo Microsserviços é uma abstração poderosa que autoriza o desenvolvimento de sistemas robustos e distribuídos, com ênfase em reduzir o acoplamento, tanto no código quanto para os times. Entretanto, como é sempre o caso, não é uma solução “bala de prata”.
A redução do acoplamento não acontece “de graça”. Há um bocado de implicações na estrutura da organização que podem tornar a adoção do estilo proibitiva. Se times monolíticos não implementam microsserviços, então será muito difícil que um time pequeno o consiga.
Também é importante informar que microsserviços demandam práticas de DevOps em “nível hard“. Ou seja, áreas de operação tremendamente maduras.
A segregação de um sistema em microsserviços também representa um grande desafio. Se feita de forma equivocada, comprometerá, pelo menos, a performance.
// TODO
Antes de avançar para o próximo capítulo, recomendo as seguintes reflexões:
- Acoplamento é um problema, hoje, para sua equipe?
- Que benefícios, para o negócio, podem ser destacados ao se desenvolver uma aplicação cloud native?



Esta autonomia é essencial para conseguir entregar os propósitos dos componentes de um sistema. Quando bem documentado gera muito desacoplamento nas entregas.
Favor ignorar esse comentário
Squads é uma ideia que nunca funcionou. Esse artigo explica os motivos:
https://www.jeremiahlee.com/posts/failed-squad-goals/