A relação de um software com artefatos externos é, ao mesmo tempo, a expressão de sua utilidade e a principal fonte de problemas em ambiente produtivo. Sejam as integrações explícitas, com esforço de desenvolvimento do time para fazer com que ela aconteça, ou implícitas, acontecendo a revelia e gerando apenas dificuldade para evolução, as integrações são aspecto crítico da arquitetura de qualquer software.
Quando as integrações não são devidamente projetadas, acontecem “organicamente”, muitas vezes como iniciativas shadow IT. Obviamente, esse é um bad smell para o futuro da solução como um todo.
 | Aplicativos interessantes raramente operam isolados. Quer seu aplicativo de vendas deva interagir com seu aplicativo de estoque, seu aplicativo de compras deva se conectar a um site de leilão ou seu PDA precise sincronizar com o servidor de calendário corporativo, parece que qualquer aplicativo pode ser melhor integrando-o com outros aplicativos. Hohpe e Woolf |
| O acoplamento forte permite que as “rachaduras” em uma parte do sistema se propaguem – ou se multipliquem – através das camadas ou limites do subsistema. Uma falha em um componente faz com que a carga seja redistribuída para seus pares e introduz atrasos e estresse para seus chamadores. Esse aumento de estresse torna extremamente provável que outro componente do sistema falhe. Isso, por sua vez, torna a próxima falha mais provável, resultando eventualmente em colapso total. Nygard |
Explicitando as relações de um software com outros
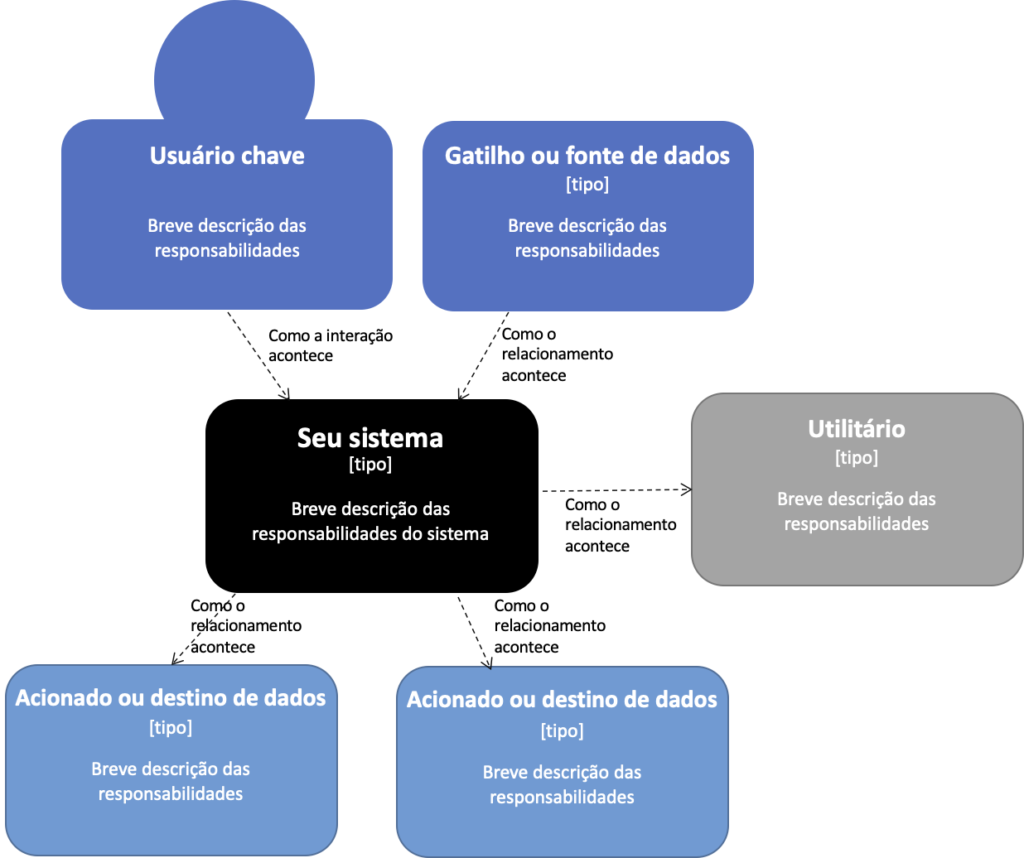
O propósito dessa análise é revelar quem são as “pessoas” (usuários, agentes, papéis ou personas) e outros artefatos (dependências externas) que estão diretamente conectadas com o software que estamos analisando. Geralmente, estes outros sistemas estão fora do escopo primário.
Embora esta seja uma análise muito simples, na prática, sua execução tem se relevando útil e desafiadora. Por incrível que pareça, é difícil para as organizações relacionar quais são os principais “acionadores” e “acionados” para os diversos sistemas. Também costuma ser bem difícil criar uma descrição sucinta sobre o que um sistema faz ou deveria fazer.
Representando relacionamentos usando o modelo C4
| O modelo C4 é uma técnica de notação gráfica enxuta para modelar a arquitetura de sistemas de software. É baseado em uma decomposição estrutural de um sistema em contêineres e componentes e depende de técnicas de modelagem existentes, como a Unified Modeling Language (UML) ou Entity Relation Diagrams (ERD) para a decomposição mais detalhada dos blocos de construção arquitetônicos. Wikipedia |
O nível mais alto de abstração proposto pelo modelo C4 propõe a elaboração de diagramas de contexto, muito semelhantes ao que indicamos aqui. Já no segundo nível, o diagrama de contêineres, “explode” o sistema que sendo analisado para revelar sua estrutura.

| Depois de entender como seu sistema se encaixa no ambiente geral de TI, uma próxima etapa realmente útil é ampliar o limite do sistema com um diagrama de contêiner. Um “contêiner” é algo como um aplicativo da web do lado do servidor, aplicativo de página única, aplicativo de desktop, aplicativo móvel, esquema de banco de dados, sistema de arquivos, etc. Essencialmente, um contêiner é uma unidade executável/implementável separadamente (por exemplo, um espaço de processo separado) que executa código ou armazena dados. O diagrama do contêineres mostra a forma de alto nível da arquitetura do software e como as responsabilidades são distribuídas por ela. Também mostra as principais opções de tecnologia e como os contêineres se comunicam. É um diagrama simples e focado em tecnologia de alto nível, útil para desenvolvedores de software e equipes de suporte/operações. Simon Brown |
A elaboração do diagrama de contêineres não é tarefa trivial.
Em sistemas muito grandes, ou legados, é comum que não seja evidente a responsabilidade de cada contêiner (indicando claro acoplamento). Em sistemas novos ou em desenvolvimento, há uma tendência de simplificar em demasia os contêineres.
O maior ganho que tenho percebido na elaboração desse diagrama está na explicitação da complexidade dos sistemas, geralmente causada por um projeto descuidado ou pela evolução descontrolada. Para sistemas novos, esse diagrama antecipa discussões que ficariam relegadas a momentos posteriores e que, se feitas no momento certo, poderiam evitar dores de cabeça.
Modelando dependências de microsserviços com modelo C4
Estratégias arquiteturais baseadas em microsserviços representam desafios para mapeamento de dependências. O problema é que, embora a relação entre dois microsserviços se assemelhe a relação de qualquer outro nível de sistema, a granularidade dificulta visualização e entendimento.
Simon Brown, criador do modelo C4 ensina que há duas abordagens comuns para modelagem de microsserviços com o modelo C4:
- Se o sistema de software depende de uma série de microsserviços que estão fora do controle do time, devemos modelar esses microsserviços como sistemas de software externos, representando o time.
- Se uma única equipe possui vários “microsserviços”, devemos modelar cada coisa implantável como um contêiner.
O mesmo é verdadeiro para funções sem servidor/lambdas/etc. Devemos tratá-los como sistemas de software ou contêineres com base na propriedade.
| Se aceitamos que as implicações da lei de Conway são reais, então, também precisamos aceitar que qualquer um que tome decisões sobre o design dos times de engenharia influencia fortemente a arquitetura do software (…) Se temos gerentes decidindo que serviços serão desenvolvidos, por quais times, implicitamente, temos gerentes decidindo a arquitetura dos sistemas. Skelton |
Principais abordagens para integração entre aplicações
- Troca de arquivos – Onde uma ou mais aplicações escrevem arquivos em um determinado formato que serão, posteriormente, processados por outra. Além do formato, é necessário estabelecer regras para como nomear os arquivos e onde estes devem ser salvos.
- Banco de dados compartilhado – com múltiplas aplicações compartilhando um mesmo esquema, localizado em um único banco (que pode ser relacional ou não). Não há, de fato, duplicação de dados e tampouco transferências.
- Replicação eventual, onde “motores de ETL” fazem cargas rotineiras de dados de determinadas fontes de dados, sem critério objetivo de seleção.
- Acionamento remoto, onde uma aplicação expõe algumas de suas funcionalidades, geralmente através de serviços e protocolos abertos, de forma que estas possam ser acessadas por outra aplicação. A comunicação é geralmente síncrona.
- Mensageria, onde uma aplicação publica mensagens para um canal comum para serem processadas por outras aplicações que “escutam” ativamente o canal.
Também há as integrações manuais, ou seja, pelo “estagiário digitador” que, partindo de um relatório, gera entradas em sistemas.
Desafios comuns em integrações
- Rede não confiável e lenta – Como bem descrito pelas “oito falácias da computação distribuída”, a rede não pode ser assumida como confiável, tampouco livre de penalidades. Não é raro que aplicações que precisam ser integradas estão operando geograficamente distantes.
- Toda aplicação é diferente (e única) – Soluções de integração precisam transmitir informações entre sistemas escritos em linguagens de programação, plataformas operacionais e formatos diferentes. Nem sempre, essa passagem é fácil.
- Mudança é inevitável – Aplicações sempre mudam ao longo do tempo (aliás, esse é o grande desafio das disciplinas de engenharia). Qualquer solução de integração precisa permanecer alinhada com essas mudanças.
As falhas da rede implicam em adotar diversas estratégias, incluindo chamadas idempotentes, handshakes, políticas de retentativa e circuit-breakers.
Para integrações com serviços externos, surgem questões relacionadas a versionamento de APIs e continuidades.
Exemplo de discussão arquitetural para integração de dados
Como fazer com que duas ou mais aplicações (potencialmente serviços ou microsserviços) que utilizam os dados de um determinado tipo de entidade, operem de forma eventualmente consistente, com o mínimo de acoplamento, sem sobrecarregar a rede e sem introduzir pontos críticos de falha?
Geralmente, fazer com que todas as aplicações utilizem o mesmo banco de dados não é a melhor escolha. Afinal, essa decisão faria com que todos os sistemas operassem de maneira extremamente acoplada tornando a evolução mais lenta. Além disso, o banco em si se converteria em um ponto crítico de falha. Por outro lado, trata-se da solução com o menor custo de desenvolvimento e parece “OK” em cenários onde o schema está estável e o time de desenvolvimento das aplicações seja o mesmo.

Desenvolver um serviço que opere como “fonte da verdade” para um determinado tipo de entidade, sendo consumido por todos os demais serviços, também não parece ser uma estratégia muito inteligente. Afinal, o acoplamento não seria em função do schema do banco de dados, mas em função do contrato do serviço. Além disso, o serviço também seria um ponto crítico de falhas (sofrendo instabilidades, comprometeria potencialmente o sistema como um todo). De qualquer forma, seria “OK” caso o volume de consumo fosse pequeno.

A melhor estratégia parece ser fazer com que cada serviço mantenha uma cópia dos dados que precisa para funcionar, pelo menos para as operações on-line. Dessa forma, seria necessário mais espaço para armazenamento (o que custa pouco), mas não haveria implicações com instabilidades externas (sem pontos de falha) e não haveria sobrecarga desnecessária na estrutura, principalmente se a frequência de modificação dos dados é pequena. De qualquer forma, trata-se da abordagem com maior complexidade associada e complexidade é custo.

A lei de Hyrum
| Com um número suficiente de usuários, não importa o que estiver acertado em contrato: todos os comportamentos observáveis de um sistema serão premissas para funcionamento de outros artefatos. Hyrum Wright |
Tal realidade é tão frequente que foi “piada” no xkcd.

Detalhes técnicos de implementação como tempos de resposta, ordenação em resultados, esquemas de bancos de dados, mecanismos de persistência e, até mesmo, detalhes de infraestrutura de uma aplicação servem, invariavelmente, como fundamento para desenvolvimento de processos e outros sistemas.
Esquemas de banco de dados, por exemplo, mesmo que oficialmente privados e restritos aos times técnicos da organização desenvolvedora, são frequentemente utilizados para desenvolvimento de mecanismos de integração.
Toda grande jornada tem um primeiro passo…
As decisões de design que se relacionam com a arquitetura garantem o atendimento dos objetivos do negócio, respeitando restrições e atingindo atributos de qualidade. Não raro, todos estes elementos tem relação direta com os relacionamentos do software que está sendo arquitetado no ambiente que irá operar.
Quanto antes os responsáveis pela elaboração da arquitetura desenvolverem familiaridade com as integrações que irão ser suportadas, maiores as chances de sucesso! Por isso, a recomendação é explicitar essas integrações no início do esforço de desenvolvimento. Além disso, garantir que os artefatos de documentação gerados se mantenham atualizados.
Explicitar as integrações do software são uma boa forma de integrar novos desenvolvedores ao time de trabalho.
// TODO
Antes de avançar para o próximo capítulo recomendo as seguintes atividades:
- Utilizando o modelo C4, desenvolva representações do software que está desenvolvendo nos níveis de contexto e contêiner.
- Pondere sobre quais abordagens de integração estão sendo utilizadas atualmente. Quais as “dores” percebidas nas escolhas feitas?
- Reflita sobre os impactos da organização dos times em sua organização na forma como as integrações são feitas
- Reflita sobre a lei de Hyrum e o software que está desenvolvendo. Há indícios de integrações desenvolvidas “apesar” das especificações?



Correção:
“A melhor estratégia parece ser: fazer com que cada serviço mantenha uma cópia dos dados que precisa para funcionar, pelo menos para as operações on-line”
faltou adicionar dois pontos no início da frase.