Importante ter clareza que mesmo arquiteturas modulares, se inadequadamente planejadas, não autorizam trabalho paralelo. Arquiteturas tecnicamente particionadas, por exemplo, são mais restritivas do que aquelas particionadas por características do domínio.
Em arquiteturas tecnicamente particionadas, quando há um time dedicado para cada componente técnico, todos os limites de componentes se convertem em “pontos de coordenação”. O impacto mais perceptível ocorre na ampliação dos lead-times.
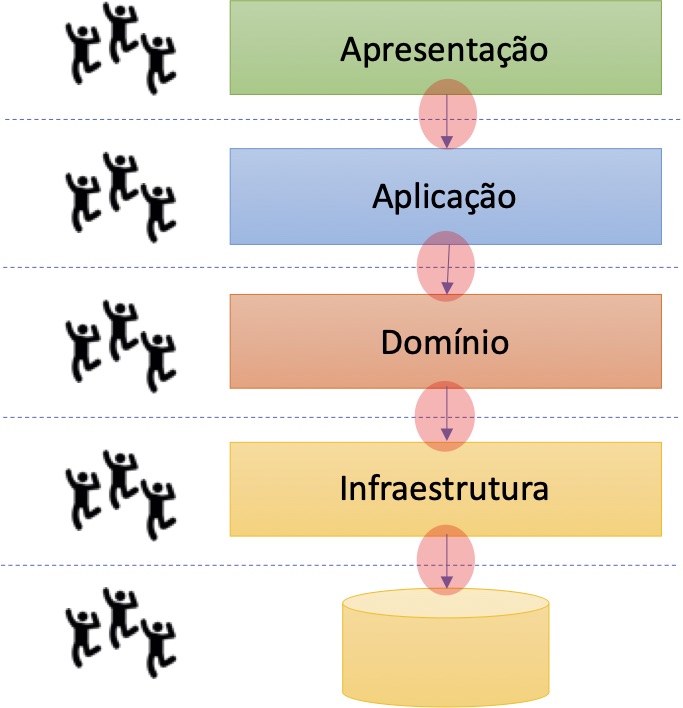
Ainda em arquiteturas tecnicamente particionadas, quando os times são organizados por features, há “difusão de responsabilidade” e queda da qualidade interna que ocasiona, também, no longo prazo, prejuízo de lead-time.

Em times maiores, arquiteturas precisam ser particionadas pelo domínio para serem sustentáveis. Essa é uma das justificativas para desenvolver arquiteturas baseadas em serviços.
Difusão de responsabilidade
De forma objetiva, um bom proxy para a difusão de responsabilidade pode ser obtido pela concentração de contribuições (commits) de diversos autores em um determinado artefato, como indicado na fórmula abaixo:

Na fórmula ai se refere a cada autor individualmente, nc(ai) é o número de contribuições para um determinado autor e, finalmente, NC é o número total de contribuições. Artefatos mantidos por um único autor tem difusão de responsabilidade zerada.
Artefatos com indicadores altos de difusão de responsabilidade geralmente apresentam qualidade interna mais baixa. A regra geral predominante parece ser “o que é responsabilidade de todos, não é de ninguém”. No fim, adaptações acabam sendo implantadas de maneira descuidada causando problemas em produção.
Particionando a “camada de negócio” em serviços
A evolução dos modelos de operação e distribuição de software, associado com o desenvolvimento de técnicas mais apropriadas de análise de domínios de negócios, autorizaram a decomposição das tradicionais “camadas de negócios” em contextos delimitados, distribuídos como serviços.

Nesse modelo, os serviços são desenvolvidos e distribuídos de forma “quase independente”, exceto por serem todos acoplados a um único banco de dados monolítico.
Para serem viáveis, tais arquiteturas são constituídas por poucos serviços. Geralmente, não menos do que 4 e não mais do que 12.
Particionando a “interface com o usuário”
Uma forma de reduzir os impactos do aumento crescente do acoplamento eferente na interface com o usuário é particioná-la também, reduzindo indiretamente os riscos de difusão de responsabilidade.
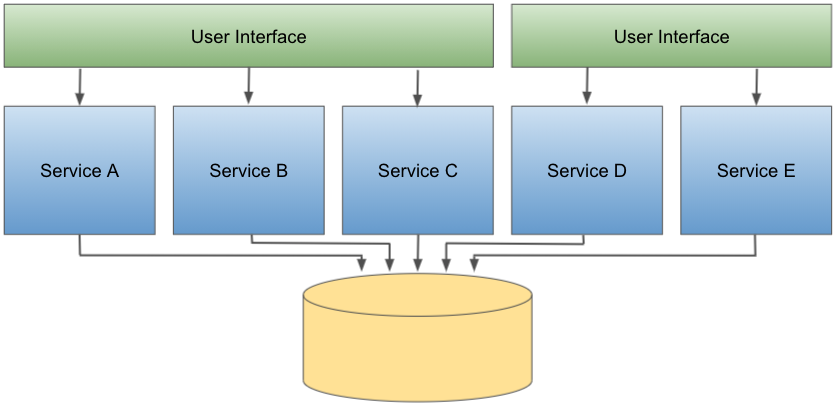
O particionamento da interface com o usuário geralmente segue os mesmos critérios de domínio aplicados nos serviços na “camada de negócios”.
A “emergência” das APIs externas

Prover uma API externa também é um bom caminho para reduzir a difusão de responsabilidade de integrações críticas e proteger o negócio.
A “emergência” de uma camada de API (gateway ou proxy)
Caso exista necessidade crescente de fazer acesso externo aos serviços de domínio, além da API externa, é uma boa prática adicionar uma camada com um proxy reverso ou gateway.

O gateway reduz o acoplamento aferente dos serviços e também é um bom mecanismo para consolidar demandas por métricas, segurança, bilhetagem, auditoria e descoberta.
Particionando logicamente o “banco de dados”
Uma saída rápida, costuma ser prover um componente com modelo de persistência para ser utilizado nos diversos serviços, suficiente para causar falhas no build quando alterações de esquema forem realizadas. O versionamento do modelo de persistência é fiel a evolução do esquema.

Em seguida, uma boa ideia é recorrer a mecanismos para particionar logicamente o banco de dados criando modelos de persistência decompostos pelos diferentes contextos delimitados. Modernamente, recursos como particionamento vertical, permitem a administração de bases de maneira inteligente, melhorando a performance.

O particionamento vertical, eventualmente, demandará um componentes com modelos de persistência também particionados para serem utilizados nos diversos serviços, suficientes para causar falhas no build quando alterações de esquema forem realizadas. O versionamento do modelo de persistência é fiel a evolução do esquema.
Particionando fisicamente o “banco de dados”
Eventualmente, há possibilidades para particionar um banco de dados monolítico em instâncias independentes, alinhadas ao domínio, de forma semelhante ao que ocorre com microsserviços.

O ponto importante, aqui, é garantir que cada banco de dados não seja necessário para outros serviços e, também, duplicação de dados, exceto quando isso for natural.
Conway, outra vez!
O particionamento pelo domínio permite a organização dos times em torno de componentes coesos, com baixa difusão de responsabilidade.
Em primeira análise, cada serviço pode ser mantido por um time independente, que é “consumido” pelo time que elabora a interface e “consome” um time de DBAs responsável pelo banco de dados. Eventulamente, o time de banco de dados pode ser também particionado conforme o serviço, bem como a interface.
Indicações e contraindicações
Particionar componentes, em última instância, demanda times particionados. Por isso, essa abordagem não é apropriada para times pequenos ou monolíticos.
// TODO
Antes de avançar para o próximo capítulo, recomendo as seguintes reflexões:
- Você conseguiria decompor seu sistema em contextos delimitados claros e independentes?
- Quais seriam as dificuldades e facilidades para particionamento da base de dados (lógico ou físico)?


