A tecnologia da informação está revolucionando os produtos. Antes compostos apenas por peças mecânicas e elétricas, os produtos se tornaram sistemas complexos que combinam hardware, sensores, armazenamento de dados, microprocessadores, software e conectividade de inúmeras maneiras. (Porter e Heppelmann)
Sob a perspectiva de sistemas computacionais um evento é um registro de algo que já aconteceu. Uma venda realizada, uma entrega efetuada, um pagamento efetivado, etc.
O aumento exponencial na quantidade de sensores e na conectividade tem feito “explodir” a quantidade e granularidade de eventos identificados em sistemas computacionais que precisam ser assimilados e tratados. Carros modernos, por exemplo, além de todos os sensores que monitoram o comportamento de seus componentes, também registram o comportamento dos condutores, identificam outros carros e as condições da pista. Neles, o software embarcado toma decisões “inteligentes” em tempo real e, eventualmente, conecta-se a outros software na “nuvem”, para realização de ações consolidadas.
A demanda por formas eficientes de lidar com eventos também é marcante em operações com cartões de crédito e sistemas de votação, detectando fraudes; em sistemas de atendimento, qualificando o processo; em sistemas de vendas, habilitando up-selling e cross-selling, apenas para citar mais alguns exemplos.
Sistemas modernos precisam reconhecer, assimilar e tratar eventos de maneira eficiente e eficaz e essa realidade fez surgir uma série de padrões e práticas arquiteturais. As arquiteturas que utilizam esses padrões e práticas são identificadas como event-driven architectures (EDAs). Elas se destacam por serem escaláveis, adaptáveis, responsivas e, geralmente, performáticas.
Diferença entre responsividade e performance
Frequentemente, há confusão entre responsividade e performance.
A responsividade é um atributo de qualidade que tem relação com o tempo que um usuário ou sistema cliente tem de esperar para, após iniciar alguma operação, poder iniciar outra.
A performance, também um atributo de qualidade, tem relação com o tempo total demandado por um sistema computacional para processar uma operação completamente.
Assim, um sistema pode ser responsivo sem ser performático.
Aplicações desenvolvidas com arquiteturas event-driven são compostas por componentes desacoplados para produção e tratamento de eventos, sempre de maneira assíncrona.
Request-driven versus Event-driven
Os benefícios gerados por arquiteturas event-driven chamam a atenção mesmo em cenários onde lidar com eventos não é necessidade primária.
A maioria das aplicações LoB (Line-of-business), por exemplo, operam, tradicionalmente, em modelo request-driven. Ou seja, onde requisições são realizadas através de interfaces com usuários, suportadas por APIs, encaminhadas para handlers que, por sua vez, fazem consultas ou atualizações em bases de dados, normalmente de forma síncrona. Esse modelo é plenamente alinhado com a realidade do domínio e geralmente apropriado. Entretanto, apresenta desafios bem conhecidos para suportar o aumento da escala sem comprometer a eficiência.
Os benefícios de arquiteturas event-driven têm levado times de tecnologia e de negócios a adaptar seus modelos de operação para que sejam compatíveis com elas, visando melhorar a responsividade e resiliência de seus sistemas. O varejo online, por exemplo, vem “desacoplando” processos de venda, segregando eventos em “pedido realizado”, “pagamento efetivado”, “produto separado”, etc.
EDA e Domain-driven design
A elaboração de arquiteturas event-driven tem sido facilitada pelo uso de Domain-driven Design.
A identificação de contextos delimitados, com suas respectivas responsabilidades, faz emergir naturalmente os “eventos de domínio”, utilizados sobretudo para a comunicação entre contextos diversos, de maneira alinhada as demandas do negócio.
Aliás, uma das técnicas mais populares para “descoberta” do domínio é centrada em eventos: event storming.
Outro ponto interessante relacionado à arquiteturas event-driven, frente a arquiteturas request-driven, é a ampliação da resiliência em função da possibilidade de tratar mensagens mal-formadas ou poison pills, sem comprometer o fluxo transacional. Afinal, mensagens “problemáticas” voltam para a fila, para retentativas, e, eventualmente, podem ser encaminhadas para filas de mensagens com problemas.
Dois tipos de EDA
De forma abstrata, podemos classificar arquiteturas event-driven em explícitas e implícitas.
Arquiteturas event-driven são explícitas quando os componentes que produzem eventos “conhecem” todos os componentes que os consomem. Nesses cenários, não é incomum que os componentes produtores acionem os consumidores diretamente, com código. Evidentemente, tal abordagem aumenta o acoplamento.
Em implementações EDA implícitas, não há qualquer “conexão fixa” entre produtores e consumidores de eventos. Assim, componentes consumidores precisam especificar, de alguma forma, os tipos de eventos em que estão interessados. Os produtores “publicam” os eventos aos consumidores através de algum mecanismo de “assinatura”, exercendo menor controle.
Duas topologias fundamentais
Há duas topologias fundamentais para implementação de arquiteturas event-driven. A primeira delas é baseada na ideia de mediadores ativos e orquestração. A segunda, é baseada na utilização de intermediadores (brokers) e coreografia.
Ambas as abordagens assumem que um “evento inicial” será capturado pelo sistema iniciando processamento.
Usando mediadores ativos e orquestração
A principal característica de uma arquitetura event-driven com mediadores ativos e orquestração é a presença de um componente orquestrador (o mediador ativo) que gerencia e controla o fluxo de atividades, acionando componentes processadores, de maneira organizada, em tempos apropriados.
Nessa topologia, explícita, um “evento inicial” é submetido a uma fila que é “escutada” pelo componente mediador. Este componente, por sua vez, “sabe” quais procedimentos que devem ser executados para “tratar” o evento e em que sequência. Por isso, aciona “executores”, notificando-os com eventos através de canais de eventos point-to-point. Toda vez que um componente executor conclui seu trabalho, geralmente notifica o componente mediador.

Os componentes executores comunicam-se apenas com o componente mediador, nunca com outros componentes executores. Enquanto isso, os componentes mediadores são a “fonte da verdade” com relação ao estágio de execução de um fluxo para tratamento de um evento.
De maneira concreta, quando o mediador exerce função ativa, direcionado o workflow, muitas vezes comunica-se enviando comandos para os diversos processadores.

Geralmente, aplicações com arquiteturas event-driven desenvolvidas nessa abordagem têm diversos componentes mediadores, algumas vezes, agrupados processos correlatos, outras vezes, ponderando estratégias para atender atributos de qualidade como disponibilidade, elasticidade e performance.
Mediadores podem ser implementados em código puro ou utilizando tecnologias como Apache Camel e Mule ESB ou Apache ODE. Há também quem defenda a utilização de ferramentas BPM (e BPA).
Usando brokers e coreografia
Diferente da abordagem utilizando mediadores e orquestração, a utilização de brokers e coreografia se destaca pela inexistência de um componente central, responsável pelo sequenciamento dos trabalhos.
Nessa topologia, implícita, componentes executores são acionados de maneira encadeada, onde um componente executor encaminha um evento para um message broker (como RabbitMQ ou outras implementações AMQP), sempre que conclui seu trabalho, acionando outro(s) componente(s) executor(es), e assim sucessivamente, até que todo o processamento necessário aconteça.

Fire-and-forget
Fire-and-forget é um padrão de mensageria onde o produtor envia uma mensagem para um consumidor sem esperar resposta. Trata-se da forma mais simples de troca de mensagens.
Fire-and-Forget destaca-se pelo baixíssimo acoplamento, afinal o produtor não precisa saber nada sobre seus consumidores, incluindo quantos existem ou o que eles fazem com a mensagem. Esse tipo de interação sem estado resulta em sistemas de mensagens altamente escaláveis.
A simplicidade e o baixo acoplamento, entretanto, tem seu preço: o tratamento de erros não é possível porque não há feedback sobre a “entrega” das mensagens. Assim, implementações Fire-and-Forget devem utilizar mecanismos mais robustos de “entrega” ou aceitarem que algumas mensagens possam ser perdidas. Além disso, é importante ter consciência de que um consumidor terá pouco a fazer caso a mensagem recebida esteja mal-formada ou com dados inválidos.
Três padrões de processamento
Componentes executores assumem, basicamente, três padrões de comportamento:
- processamento simples;
- processamento de streams;
- processamento de eventos complexos (complex event processing – CEP).
Enquanto o padrão de processamento simples ocorre tanto arquiteturas orquestradas e coreografadas, processamento de streams e de eventos complexos costumam ser implementadas apenas em topologias coreografadas.
O detalhamento desses padrões de execução estão além do escopo desse livro. Aliás, há obras inteiras dedicadas ao tema.
Processamento simples
Componentes executores que operam adotando processamento simples, “escutam” um determinado tipo de mensagem e executam, para cada ocorrência, algum trabalho. Trata-se do padrão mais fácil de implementar e, provavelmente, mais comum.
Processamento de streams
Componentes executores que operam adotando processamento de streams, podem “escutar” diversas ocorrências de eventos mas só executam algum processamento quando algum critério é atendido. Estes executores operam agregando, analisando e processando streams de eventos.
Considere, por exemplo, um componente executor recebendo todas as transações de um determinado cartão de crédito. Caso duas transações presenciais (dois eventos) sejam executadas em localidades afastadas a uma distância maior do que aquela que poderia ser percorrida no intervalo de tempo entre as ocorrências, este executor poderia gerar um evento (agregação) indicando possibilidade de fraude.
Processamento de eventos complexos (CEP)
Componentes executores que operam adotando processamento de eventos complexos, identificam eventos significativos (como oportunidades ou ameaças) a partir de eventos menos expressivos, oriundos de dois ou mais streams.
Sagas
Em aplicações monolíticas, geralmente, temos um frontend conectando a um único serviço que, por sua vez, se conecta a apenas um banco de dados que serve como a “grande fonte da verdade”. Por mais complexas que sejam as operações, podemos usar, quase sempre o recurso de transações do banco de dados para garantir a preservação da consistência.
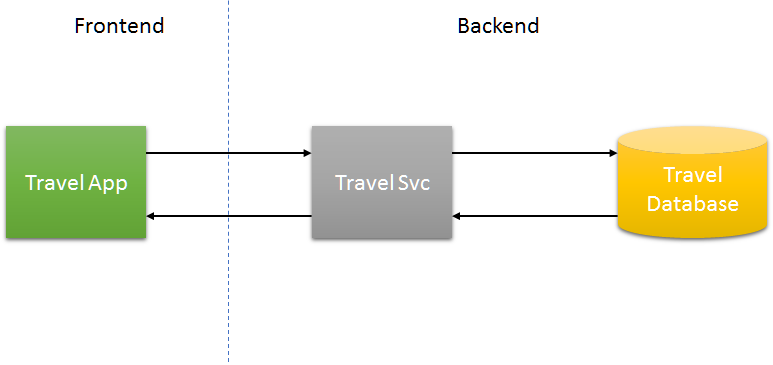
Imaginemos, entretanto, que não seja possível estabelecer uma “fonte única de verdade” ou, ainda, que a arquitetura da aplicação utilize mais que um banco de dados (conforme contexto delimitado). Vamos considerar, por exemplo, o desenvolvimento de um serviço para apoiar a compra de produtos associados a viagens. Nesse contexto, desejaríamos ajudar nossos clientes na aquisição de bilhetes aéreos, no aluguel de carros e na reservas em hotéis.

No “mundo perfeito”, sempre que um cliente resolvesse viajar, poderíamos disparar a compra do bilhete aéreo, a reserva do hotel e do carro de forma paralela. Nosso trabalho seria apenas consolidar as confirmações em nosso “banco de dados” para poder fornecer ao cliente as informações de cada serviço contratado. Mas, o que aconteceria se:
- Não houvesse hotel disponível para a cidade escolhida pelo nosso cliente?
- Não houvesse a opção de carro que o cliente precisa?
- Não houvesse opção viável de voo?
Na prática, provavelmente, a falha de qualquer uma dessas operações implicaria no cancelamento da viagem. Entretanto, perceba que, agora, não temos uma “transação” para dar rollback. A saída empírica é executar uma atividade compensatória (cancelamentos) anulando os efeitos produzidos nos serviços que foram completados com êxito.
No nosso exemplo, se tivessemos êxito em reservar o hotel e o carro, mas houvesse uma falha na compra do bilhete aérero, teríamos que “voltar” aos serviços fornecidos pelo hotel e pela locadora de automóveis para cancelar reservas. Para tornar o cenário ainda mais desafiador, precisaríamos entender as implicações destes cancelamentos para evitar multas, por exemplo. A solução é implementar o padrão Sagas.
Saga é uma transação de longa duração que pode ser escrita como uma sequência de transações independentes e intercambiáveis. Todas as transações na sequência devem ser completadas com êxito. Caso contrário, ações compensatórias são executadas para desfazer os efeitos da execução parcial.
Em nosso exemplo, a saga “Viagem do Elemar” seria composta por três transações independentes: 1) Compra da Passagem Aérea; 2) Reserva do Hotel e 3) Reserva do Carro.

Cada transação na Saga, tem uma ação compensatória capaz de “desfazer” uma transação parcial bem-sucedida.

A implementação mais simples para a saga seria através de um componente orquestrado: saga events coordinator

Trata-se de uma especialização da topologia proposta para trabalhar com um componente mediador. O início das atividades, para o SEC, pode ocorrer com um evento inicial e as respostas dos serviços especializados ocorre com eventos de conclusão.
Event sourcing
Fazer com que um sistema lance eventos de notificação para toda modificação no estado de uma entidade abre espaço para algumas soluções interessantes. Podemos, por exemplo, usar os eventos de notificação para, além de permitir implementação desacoplada de consistência eventual entre aplicações, contar a “história” de entidades, através de uma técnica conhecida como Event Sourcing.
A ideia central da técnica é reconhecer que o estado de uma entidade é “explicado” pela ocorrência de uma sequência clara de eventos, em uma ordem determinada.
Com posse do histórico de eventos de notificação de alteração de estado, podemos restituir qualquer um dos “estados históricos” de uma entidade, bastando, para isso, que realizar um replay do seu histórico de eventos até o ponto apropriado.

Em termos simples, matendo o histórico de eventos armazenado, podemos “recuperar” o estado de uma entidade, em qualquer momento. Podemos também saber quando mudanças ocorreram, quem fez essas mudanças e qual foi a intenção de negócio. Poderoso, porém complexo!
Sistemas que usam event sourcing costumam manter, além da base de eventos, uma outra base com materializações do estado da entidade em algum momento (geralmente o atual).

Essa materialização é útil por ser extermamente fácil de pesquisar. Podemos pensar essas materializações como “fotografias” do estado da entidade em algum momento. Talvez por isso, convencionou-se utililizar a designação snapshot.
A base de dados utilizada para armazenar eventos geralmente é nosql (o NuBank, por exemplo, utiliza Datomic para registrar transações). A base para os snapshots pode ser quaquer uma, inclusive relacionais. Aliás, Greg Young, que formalizou o conceito de Event Sourcing, criou um banco de dados para armazenar eventos chamado EventStore.
Reatividade natural
Arquiteturas event-driven, quando bem implementadas, são naturalmente reativas. Ou seja, são responsivas, resilientes, elásticas e orientadas a mensagens.
A responsividade é natural ao processamento assíncrono, comum em EDAs.
A resiliência, por sua vez, é garantida pela estabilidade dos mecanismos de mensageria, que “seguram” os eventos caso exista alguma instabilidade nos componentes processadores.
A elasticidade é possível graças ao desacoplamento dos componentes executores dos demais. Em princípio, quando a demanda sobe pela ocorrência de mais eventos, componentes executores mais pesados podem ter novas instâncias criadas e descartadas conforme a escala oscila.
Por fim, o “fluxo dos eventos” é, quando é usado um mecanismo adequado de mensageria, naturalmente orientado a mensagens.
Conway, outra vez!
Arquiteturas event-driven geralmente são particionadas pelo domínio, o que facilita a formação de times especialistas para características do negócio.
Indicações e contraindicações
// TODO
Antes de avançar para o próximo capítulo, faça as seguintes reflexões:
- O sistema em que está trabalhando agora lida, naturalmente, com eventos?
- Baseado em sua experiência, com que frequência o aumento da complexidade justificaria “transformar” sistemas request-driven em event-driven?
- Sistemas escaláveis são, geralmente, assíncronos. Concorda com essa afirmação?
- Em que cenários adotaria Event Sourcing?



Boa noite pessoal,
Corrigir>>> Essa materialização é útil por ser extermamente fácil de pesquisar
Para>>> Essa materialização é útil por ser extremamente fácil de pesquisar