Revisitando 'Arquitetura' e o 'Papel do Arquiteto'
A arquitetura de um software tem relação com as decisões de design que contribuem para os objetivos do negócio, respeitando restrições e atingindo atributos de qualidade.
O projeto da arquitetura vai determinar quais serão os componentes de uma aplicação, as responsabilidades de cada um desses componentes e a forma como se relacionam, além da estratégia de evolução, sempre perseguindo evolvability.
Por implicações da lei de Conway, a arquitetura do software é diretamente impactada pelas organizações dos times, e vice-versa. Logo, a arquitetura tem implicações diretas sobre as demandas de coordenação e sincronização e, indiretamente, pela eficiência operacional.
O arquiteto de software, evidentemente, precisa ser sensível a todas essas implicações e desenvolver habilidades para ponderar em dimensões que, evidentemente, extrapolam tecnologia.
Importante ter clareza que mesmo arquiteturas modulares, se inadequadamente planejadas, não autorizam trabalho paralelo. Arquiteturas tecnicamente particionadas, por exemplo, são mais restritivas do que aquelas particionadas por características do domínio.
Em arquiteturas tecnicamente particionadas, quando há um time dedicado para cada componente técnico, todos os limites de componentes se convertem em “pontos de coordenação”. O impacto mais perceptível ocorre na ampliação dos lead-times.
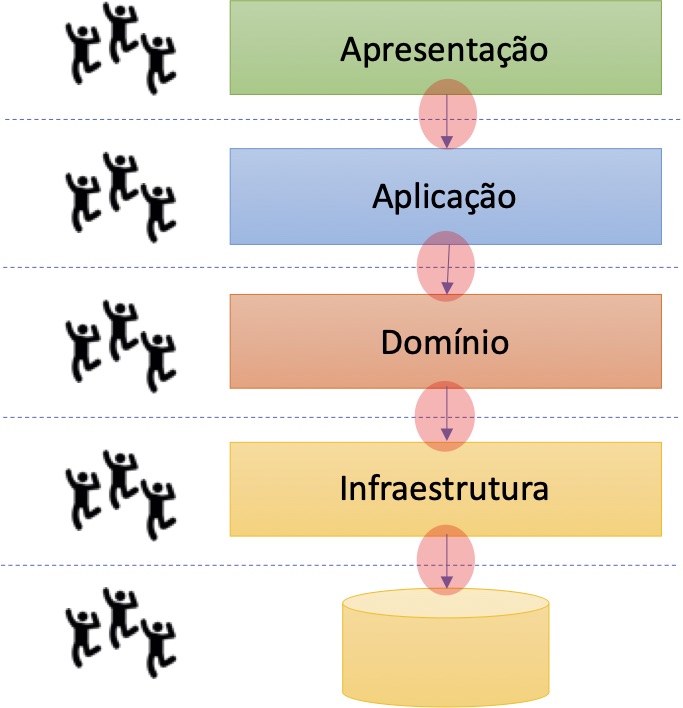
Ainda em arquiteturas tecnicamente particionadas, quando os times são organizados por features, há “difusão de responsabilidade” e queda da qualidade interna que ocasiona, também, no longo prazo, prejuízo de lead-time.

Two-pizzas rule
Jeff Bezos, fundador da Amazon, argumentou que o número ideal de membros em um time é aquele onde todos possam ser alimentados com duas pizzas – geralmente, sete pessoas. Esse posicionamento ficou conhecido como “The two pizzas rule”.
Times pequenos apresentam menos desafios para comunicação, reduzindo também problemas de coordenação e sincronização. Em uma arquitetura em quatro camadas, tradicional, com um time responsável por cada camada, teríamos então um limite razoável de 30 pessoas – mas geralmente esse número seria menor, não mais do que 20, afinal, as “alocações” na gestão do banco, por exemplo, pelo seu alto acoplamento aferente são menores. No mesmo modelo em camadas, uma tentativa de separar times por contexto delimitado, sem “colapsar” o código, restringe o número de times a, no máximo, três (~20 pessoas).
Difusão de responsabilidade
Desenvolver software é um “esporte coletivo” e qualquer atividade em grupo tem demandas de coordenação. Quanto mais desenvolvedores tocam am um trecho de código, maiores são as chances de que este código tenha defeitos e, além disso, maiores são os custos operacionais de gestão. Quanto maior o número de envolvidos, mais importantes, frequentes e custosas são atividades de comunicação e de coordenação. Analogamente, mais difusa é a responsabilidade pela qualidade.De forma objetiva, um bom proxy para a difusão de responsabilidade pode ser obtido pela concentração de contribuições (commits) de diversos autores em um determinado artefato, como indicado na fórmula abaixo:

Na fórmula ai se refere a cada autor individualmente, nc(ai) é o número de contribuições para um determinado autor e, finalmente, NC é o número total de contribuições. Artefatos mantidos por um único autor tem difusão de responsabilidade zerada.
Git como 'rede social'
Ferramentas modernas de controle de versão são frequentemente usadas apenas como mecanismos sofisticados de backup de código-fonte. Entretanto, podem ser bem mais do que isso.
O Git, por exemplo, consegue apontar arquivos que são modificados com mais frequência, colaboradores mais ativos, além, é claro, parâmetros para cálculo da difusão de responsabilidade. A instrução 'git shortlog -s', por exemplo, relaciona a quantidade de commits , por desenvolvedor, em uma determinada pasta.
Artefatos com indicadores altos de difusão de responsabilidade geralmente apresentam qualidade interna mais baixa. A regra geral predominante parece ser “o que é responsabilidade de todos, não é de ninguém”. No fim, adaptações acabam sendo implantadas de maneira descuidada causando problemas em produção.
Curiosamente, artefatos com maior difusão de responsabilidade costumam ser, também, aqueles que tem maior acoplamento eferente e que, por isso, quebram com mais facilidade, ou com maior acoplamento aferente, com potencial para gerar prejuízos maiores no sistema, caso apresentem defeito.Arquiteturas particionadas por domínio tendem a ter artefatos com difusão de responsabilidade mais baixa. Artefatos com difusão de responsabilidade mais baixa tendem a ser mais fáceis de manter e evoluir, o que converte essa métrica em uma boa fitness function.
Propriedade sobre artefatos
A atribuição de “propriedade” para artefatos de um software – como documentação, código, banco de dados, etc – é um tema controverso. Muitas pessoas associam “propriedade” como justificativa para redução da colaboração ou, pior ainda, formação de silos. Entretanto, esse não é o ponto! A atribuição de “propriedade” é uma medida para tentar minimizar os efeitos da difusão de responsabilidades.
Atribuir “propriedade” de artefatos a times ou indivíduos é similar a iniciativa de atribuir mantenedores para projetos open source. Ou seja, determinar responsabilidade pela qualidade atual e futura de um artefato para alguém que irá o “zelar e protejer”.
A “propriedade” de artefatos não é uma maneira de coibir contribuições, muito pelo contrário, é um incentivo para participação ativa. Cabe aos “proprietários” arbitrar, apenas, que contribuições estão prontas para serem aceitas.
Artefatos sem um “dono” são órfãos. Aliás, é um cenário comum nas organizações que “donos” de artefatos deixem a empresa e, consequentemente, deixem seus “artefatos filhos” desprovidos de cuidado – daí, logo, “difusão de responsabilidade”.
Particionando a “camada de negócio” em serviços
A evolução dos modelos de operação e distribuição de software, associado com o desenvolvimento de técnicas mais apropriadas de análise de domínios de negócios, autorizaram a decomposição das tradicionais “camadas de negócios” em contextos delimitados, distribuídos como serviços.

Nesse modelo, os serviços são desenvolvidos e distribuídos de forma “quase independente”, exceto por serem todos acoplados a um único banco de dados monolítico.
Domain-driven Design
Eric Evans escreveu, em 2003, o livro ‘<em>Domain-driven Design</em>’. Trata-se de uma formalização de práticas e padrões para, segundo o autor, atacara complexidade no coração do software.
Um dos fundamentos de <em>Domain-driven Design</em> é identificar, dentro de um determinado domínio de negócio, subdomínios que, mais tarde, são modelados em contextos delimitados. Na modelagem de sistemas da forma como apresentamos aqui, cada contexto delimitado pode ser “implementado” como um serviço
Para serem viáveis, tais arquiteturas são constituídas por poucos serviços. Geralmente, não menos do que 4 e não mais do que 12.
O problema com 'Kernel Compartilhado'
Domain-driven Design autoriza a identificação e implementação de kernels compartilhados: parte do modelo de domínio de uso comum para dois ou mais contextos delimitados. Entretanto, antes de solução, este tipo de artefato representa problema.
Kernels compartilhados são naturalmente acoplados (de maneira aferente) e nascem com difusão de responsabilidade alta. Eventualmente, representam redução dos custos de desenvolvimento, mas, seguramente, representam acréscimo no custo de manutenção.
Particionando a “interface com o usuário”
Uma forma de reduzir os impactos do aumento crescente do acoplamento eferente na interface com o usuário é particioná-la também, reduzindo indiretamente os riscos de difusão de responsabilidade.
Não é raro que diferentes perfis de usuários demandem e valorizem características diferentes de usabilidade. Por exemplo, enquanto vendedores tendem a valorizar simplicidade e objetividade, analistas financeiros geralmente gostam dor maior volume de informações concentrado (com menos espaços em branco). Por isso, antes de ser um problema, o particionamento da interface pode ser uma “solução” para a inclusão de adaptações, com coesão de padrões de projeto de UX.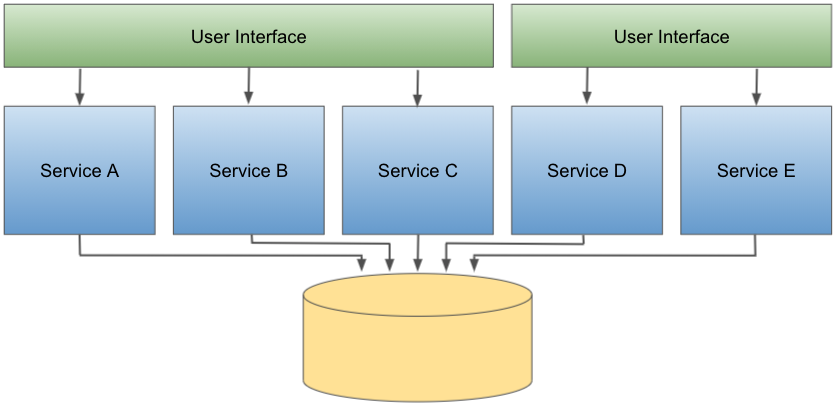
O particionamento da interface com o usuário geralmente segue os mesmos critérios de domínio aplicados nos serviços na “camada de negócios”.
A “emergência” das APIs externas
Eventualmente, serviços internos irão interagir diretamente com sistemas de terceiros que irão oferecer uma “interface alternativa” para alguns “serviços de negócios” de um software. Nesses casos, pode ser uma boa ideia oferecer um serviço específico para atender às demandas desse serviço externo, reduzindo acoplamento eferente externo (e as chances de quebra).
Prover uma API externa também é um bom caminho para reduzir a difusão de responsabilidade de integrações críticas e proteger o negócio.
A “emergência” de uma camada de API (gateway ou proxy)
Caso exista necessidade crescente de fazer acesso externo aos serviços de domínio, além da API externa, é uma boa prática adicionar uma camada com um proxy reverso ou gateway.

O gateway reduz o acoplamento aferente dos serviços e também é um bom mecanismo para consolidar demandas por métricas, segurança, bilhetagem, auditoria e descoberta.
Particionando logicamente o “banco de dados”
A decomposição da “camada de negócios” em serviços e da “camada de interface” em experiências independentes, implicam no aumento do acoplamento aferente do banco de dados, o que é um problema em potencial, mesmo com o número reduzido de serviços (geralmente, 7 em arquiteturas assim). Se não forem feitas de maneira apropriada, alterações de esquema podem causar problemas nos diversos serviços, o que aumenta bastante a necessidade de coordenação.Uma saída rápida, costuma ser prover um componente com modelo de persistência para ser utilizado nos diversos serviços, suficiente para causar falhas no build quando alterações de esquema forem realizadas. O versionamento do modelo de persistência é fiel a evolução do esquema.

Em seguida, uma boa ideia é recorrer a mecanismos para particionar logicamente o banco de dados criando modelos de persistência decompostos pelos diferentes contextos delimitados. Modernamente, recursos como particionamento vertical, permitem a administração de bases de maneira inteligente, melhorando a performance.

O particionamento vertical, eventualmente, demandará um componentes com modelos de persistência também particionados para serem utilizados nos diversos serviços, suficientes para causar falhas no build quando alterações de esquema forem realizadas. O versionamento do modelo de persistência é fiel a evolução do esquema.
Particionando fisicamente o “banco de dados”
Eventualmente, há possibilidades para particionar um banco de dados monolítico em instâncias independentes, alinhadas ao domínio, de forma semelhante ao que ocorre com microsserviços.

Composição interna de um serviço
A estrutura interna dos serviços em arquiteturas particionadas pelo domínio costuma ter uma façade, lógica de negócios e o modelo de persistência.

Eventualmente, cada serviço poderá ser estruturado seguindo o modelo hexagonal, proposto por Alistair Cockburn (a imagem abaixo foi extraída do site de Cockburn).

Para serviços maiores e mais complexos, pode ser interessante, estruturar, decompor, internamente, o serviço em componentes isolados abrindo margem para implementações futuras baseadas em microsserviços.
Cuidado com a complexidade
A complexidade tem quatro origens genéricas distintas que devem ser combatidas. São elas: dimensionalidade, interdependência, influência do ambiente e irreversibilidade.
Sistemas mais “sensíveis” ao ambiente também são mais complexos. Afinal, demandam planejamento de contingências e workarounds. Da mesma forma, times mais “sensíveis” a influências externas também precisam se preparar para contingências e workarounds.
Finalmente, a irreversibilidade também demanda cuidados. Ações ou eventos cujo ocorrências resultem em consequências que não podem ser desfeitas implicam em custo maior de planejamento, nem sempre eficiente. Daí, a ênfase para servidores imutáveis, principalmente para sistemas com índice maior de particionamento.
Conway, outra vez!
O particionamento pelo domínio permite a organização dos times em torno de componentes coesos, com baixa difusão de responsabilidade.
Em primeira análise, cada serviço pode ser mantido por um time independente, que é “consumido” pelo time que elabora a interface e “consome” um time de DBAs responsável pelo banco de dados. Eventulamente, o time de banco de dados pode ser também particionado conforme o serviço, bem como a interface.
Indicações e contraindicações
A abordagem arquitetural disposta nesse capítulo destaca-se pelo pragmatismo. Embora, como arquitetura distribuída, a decomposição em poucos serviços seja menos “ambiciosa” do que abordagens mais extremas, como microsserviços, trata-se de um modelo “mais fácil de pagar”.A decomposição por contextos tem fit natural com análises baseadas em Domain-driven Design. Além disso, a “tolerância” a um banco de dados monolítico autoriza transações ACID.
Particionar componentes, em última instância, demanda times particionados. Por isso, essa abordagem não é apropriada para times pequenos ou monolíticos. Assumindo, aliás, que o tamanho ideal de times de tecnologia é de 7 pessoas e que haverá um time para cada serviço, podemos inferir que este estilo arquitetural funciona bem para equipes de até 100 pessoas.
// TODO
Antes de avançar para o próximo capítulo, recomendo as seguintes reflexões:
- Você conseguiria decompor seu sistema em contextos delimitados claros e independentes?
- Quais seriam as dificuldades e facilidades para particionamento da base de dados (lógico ou físico)?


